- 머신러닝 기초 공부; CNN2023년 12월 16일 04시 50분 07초에 업로드 된 글입니다.작성자: Taeyong, Lee.
머신러닝 공부
- 머신러닝 기초 공부; SLP, MLP
- 머신러닝 기초 공부; Adam
- 머신러닝 기초 공부; CNN
우리는 여러 가지 형태의 데이터를 분석한다. 간단하게는 테이블이 있고, 화면과 같은 이미지, 시간에 따른 변화나 어떤 열을 따라 변화하는 것을 기록한 시계열, 이 둘을 합한 동영상 등이 있다. 여기에선, 이미지 데이터를 처리하는 것을 자세하게 다룰 것이다. 이미지 데이터는 보통 2차원의 넓은 면을 가지고 각 포인트마다 값을 갖는다. 많은 수의 픽셀을 갖는 이미지의 경우 입력 벡터의 크기가 커지고, weight 파라미터 개수가 엄청 커지게 된다. 또한, 이미지를 파악할 때는 주위의 데이터가 중요하게 작용한다. 예를 들어, 이미지의 사람을 인식해야 한다면, 사람 모양의 픽셀을 파악하는 게 중요하고 안에 사람의 특징을 가지는 지 파악해야 할 것이다. 이런 이미지 데이터 분석의 특징을 반영하여 고안된 방식이 합성곱 신경망(Convolutional neural network, CNN)이다.
Convolution layer의 계산
Convolution layer(합성곱 계층)에서 수행하는 Convolution은 수학에서 흔히 쓰이는 Convolution의 구조와 조금 닮아 있으며, 커널(kernel)이라고 부르는 작은 가중치 텐서를 이용하여 구성한다. 이후, Pooling layer(풀링 계층)를 통해, 처리할 이미지 해상도를 줄이면서 정보를 압축한다. 한 계층에서 같은 커널을 적용하기 때문에, 이미지 전체에서 정보를 종합하는 효과가 있고, 이는 넓은 픽셀에 완전 연결 계층을 사용할 때보다 확연히 적은 파라미터를 이용하게 된다. 커널 모양 대로 이미지의 정보를 계속해서 종합하게 되고, 이후 풀링을 통해 주위 정보에 대한 정보를 압축하게 되면서, 패턴을 파악하는 원리이다. 이 과정을 도식으로 나타내면 아래와 같다.

Convolution layer의 커널과 편향 정보 예시. 위 예시에서, Convolution 계산은 회색 영역과 커널을 element-wise 곱한 후 모든 값을 더하고 bias를 더해주는 방식으로 계산한다. 즉, $1\cdot 2 + 2 \cdot 0 + 8 \cdot 1 + 1 \cdot (-1) + 1 \cdot 0 + 2 \cdot 1 + 2 \cdot 2 + 6 \cdot 1 + 9 \cdot 0 -1 = 20$이다. 정보가 압축되면서 자연스럽게 Convolution layer의 출력값은 입력값과 다른 크기를 가질 수 있다. 하지만, 목적에 따라 같은 크기를 갖게 만들 수도 있다.
Convolution layer 출력의 크기
Convolution 과정에서, 출력 픽셀값을 계산하기 위해 입력 영역을 설정하다 보면, 커널의 크기에 따라 확장될 때가 있다. 이렇게 확장하는 것을 padding(패딩)이라고 부른다. 우리는 패딩 없이, 유효한 부분에서의 값만 취할 수도 있고, (0으로) 패딩을 적용하여, 같은 크기를 갖게 출력을 만들 수도 있다. 유효한 입력 범위에서만 계산하는 것을 valid padding이라고 하고, 입력 범위를 확장하여 0으로 둘러싸 출력을 입력 이미지 크기와 같게 하는 것을 same padding이라고 한다. 위 예시를 활용하면 아래와 같이 입력을 바꾸는 것이다. 커널이 $3\times 3$ 크기이기 때문에 상하좌우 1칸을 0으로 둘러싸면 충분하다.

Same padding 방식으로 변한 입력. Convolution layer 순전파
입력값을 $x$, 출력값을 $y$라고 하고, same padding을 적용한 convolution layer를 가정해 보자. 출력값의 좌표와 입력값의 좌표는 커널과 어떤 관계에 있는지 정확히 알고 있어야, 코딩하기 편해진다. Padding은 실제로 $x$에 추가하진 않고, 범위를 벗어나면 값을 0으로 취급한다. $m$번째 미니배치 데이터의 $n$번째 커널, $r$ 행, $c$ 열의 출력 $y$를 구하기 위해서 어떤 값이 필요한 지 살펴보자. Convolution layer의 입력 $x$ 중에, $k_h\times k_w$ 사이즈의 커널 $k$을 가지고 구한다면, 어느 좌표를 사용하는지 알면 된다. 이미지의 두 개의 축을 한 번에 생각하기보다, 하나의 축만 살펴보자. 즉, 아래 그림처럼 1차원 축으로만 생각해 보자.

크기 5의 커널을 이용할 때 필요한 인덱스 위 그림은 5 크기를 갖는 커널을 이용할 때, 출력 좌표 $r$의 값을 구하기 위해서, 어떤 입력 좌표가 필요한 지 나타내는 그림이다. 이것을 수식으로 정리하면 아래와 같다 (일단, $c$ 좌표는 무시하자).
$$y_{n,r,c,m} = k_{0,j,l,m}x_{n,r-2,c,l}+k_{1,j,l,m}x_{n,r-1,c,l}+k_{2,j,l,m}x_{n,r,c,l}+k_{3,j,l,m}x_{n,r+1,c,l}+k_{4,j,l,m}x_{n,r+2,c,l}$$
입력 $x$와 $y$는 [미니배치, 행, 열, 채널] 순서로 인덱스를 가지고 있고, 커널 $k$는 [행, 열, 입력 채널, 출력 채널] 순서의 인덱스를 가지고 있다. 위 그림에서 볼 수 있듯, 크기 5의 커널을 이용한다면, $r$을 기준으로 2 인덱스 전, 후의 인덱스를 이용하는 것을 알 수 있다. 커널의 인덱스를 $i$라고 하면, $r$에서 2 인덱스 전부터 하나씩 높여가며 입력 $x$에서 가져오면 된다. 그렇다면, 5 크기의 커널과 2 인덱스 전부터 가져오는 것은 어떤 관련이 있을까?
홀수 크기의 커널만을 먼저 생각해 보자. 크기가 3,5,7,...로 증가함에 따라서, 필요한 인덱스가 점점 더 밀릴 것이다. 얼마큼 밀리게 될지, 아래 그림을 참고해 보자.

홀수 크기를 갖는 커널에서 $r$의 출력값을 만들기 위해 필요한 입력 데이터의 인덱스. 위 그림에서 볼 수 있듯, 크기가 2 증가할 때마다, 필요한 시작 좌표가 1씩 늘어난다. 즉, 크기 $k_h$에 따라, 시작 좌표가 $r-\frac{k_h-1}{2}$에서 시작하게 된다. 즉, 커널의 크기가 홀수 일 때, 입력 채널 $l$을 이용하여, 출력의 채널 $m$을 구하는 것은 아래와 같이 식을 적을 수 있다.
$$ y_{n,r,c,m} = k_{0,j,l,m}x_{n,r-\frac{k_h-1}{2},c,l}+k_{1,j,l,m}x_{n,r+1-\frac{k_h-1}{2} ,c,l}+k_{2,j,l,m}x_{n,r+2-\frac{k_h-1}{2} ,c,l}+\cdots +k_{k_h-1,j,l,m}x_{n, r+\frac{k_h-1}{2},c,l}=\sum^{k_h-1}_{i=0} k_{i,j,l,m}x_{n,r+i-\frac{k_h-1}{2},c,l} $$
모든 입력 채널을 사용한다면, 아래와 같다.
$$ y_{n,r,c,m} = \sum^{k_h-1}_{i=0} \sum^{x_{chn}-1}_{l=0} k_{i,j,l,m}x_{n,r+i-\frac{k_h-1}{2},c,l} $$
짝수 크기의 커널도 마찬가지로, 그림으로 알아보자. 아래 그림에서 알 수 있듯, 짝수 크기의 커널은 경계 부근에서 비대칭이 일어난다.

짝수 크기를 갖는 커널은 경계에서 비대칭을 일으킨다. 커널 크기가 짝수이기 때문에, 중심을 갖는 좌표를 정할 수 없고, padding 또한 비대칭적으로 일어난다. 만약, padding을 갖게 조정한다면, 출력의 크기에 왜곡이 생길 것이다. 그래서, 짝수 크기의 커널은 잘 사용하진 않는다. 우리 교과서에서는 일관성을 위하여, 위 홀수 크기의 경우의 값을 동일하게 사용하나, 값이 소수가 나오므로 이를 방지하기 위해 정수 나눗셈 연산자 (
//)를 사용하게 된다. 즉, 최종적으로, 두 축을 모두 더하여, 아래와 같은 수식을 사용한다. $ b_h = \lfloor \frac{k_h-1}{2} \rfloor, b_w = \lfloor \frac{k_w-1}{2} \rfloor$라고 하면,$$ y_{n,r,c,m} = \sum^{k_h-1}_{i=0} \sum^{k_w-1}_{j=0} \sum^{x_{chn}-1}_{l=0} k_{i,j,l,m}x_{n,r+i-b_h,c+j-b_w,l} $$
위와 같이 구할 수 있다. 이제 이 과정을 python으로 구현해 보자.
Convolution layer 순전파 구현
Convolution layer 순전파를 계산하는 것을 교과서에선 3가지를 제안한다. 최대한 많은 반복문을 사용하는 경우에서부터, 간단하게 행렬곱을 만드는 경우까지 하여 3가지를 제안하는데, 마지막 경우만 여기에서 설명하려 한다. 위에 과정을 보면 바로 알 수 있지만, 여러 번의 반복문을 사용하면, 매우 쉽게 코딩할 수 있다. 하지만, C나 C++과 같은 low-level 언어가 아닌 경우 (Python, Matlab, Mathematica 등과 같이) 반복문을 여러 번 사용하는 것은 효율이 나쁘다. 누군가는 기초적인 인덱싱도 제대로 되어있지 않은 상황이라고 까지 표현한다. 즉, 인간 언어에 가까운 언어를 사용할수록, 행렬 연산이 있는 numpy 패키지 활용하여, 코드 최적화를 구현 단계와 구별하는 게 좋다.
교과서에서 제공하는 순전파 코드는 앞서 말한 바와 마찬가지로 3단계를 모두 제공하지만, 마지막 단계에 있는 것은 조금 이해하기 어렵다. 하지만, 출력을 기준으로 생각하면, 쉽게 이해할 수 있다. 2차원 이미지를 주로 다루겠지만, 일단 이해를 위해 1차원 데이터가 제공되고, 출력된다고 생각하자. 그리고, 간단하게 보기 위하여, same padding의 경우를 구현할 것이고, 미니배치는 1개만 존재한다고 하자. 그렇다면, convolution layer의 순전파 과정은 아래와 같이 표현할 수 있다.

간단화된 구조. 각 숫자는 각 변수의 인덱스를 말한다. 출력과 입력이 같은 크기이기 때문에, 출력을 기준으로 어떤 입력이 필요한 지 살펴보자. 일단, 모든 좌표에서 같은 커널을 공유하기 때문에, 커널은 따로 건들 필요가 없다. 그리고, 이 경우 입력과 출력의 채널이 모두 1개이고, 1차원이기 때문에, 모양도 또한 바꾸지 않아도 된다.
다음은 입력이다. 각 출력에서 필요한 입력의 좌표는 모두 다를 것이다. 경계선에 있는 경우엔, padding이 필요할 것이고, 아닌 경우엔, 위에서 설명했듯, 좌표의 $b_h$ 전 좌표부터 $b_h$ 후까지의 좌표가 필요하다. 즉, 우리는 각 입력 좌표에서, 필요한 입력을 지니고 있는, 입력 변수를 가지고 있다면, 커널과의 행렬 곱으로 나타낼 수 있다. 즉, 입력을 다음과 같이 변화시켜야 한다.
def get_ext_regions(x, kh, kw, fill): # 차후 풀링 연산에서 재사용을 위함 mb_size, xh, xw, xchn = x.shape eh, ew = xh + kh - 1, xw + kw - 1 bh, bw = (kh-1)//2, (kw-1)//2 x_ext = np.zeros((mb_size, eh, ew, xchn), dtype='float32') + fill # 0이 아닌값으로 padding x_ext[:, bh:bh + xh, bw:bw + xw, :] = x # padding을 지니는 extended x 변수 완성 regs = np.zeros((xh, xw, mb_size*kh*kw*xchn), dtype='float32') # 각 좌표에 필요한 입력을 담을 변수 for r in range(xh): # 해당되는 원소들을 찾아 저장. for c in range(xw): # 각 좌표에 변수를 (1차원으로) 저장 regs[r, c, :] = x_ext[:, r:r + kh, c:c + kw, :].flatten() # 결과적으로 [xh, xw, mb_size X kh X kw X xchn] 크기의 텐서가 얻어짐 return regs.reshape([xh, xw, mb_size, kh, kw, xchn]) # reshape해서 반환 def get_ext_regions_for_conv(x, kh, kw): mb_size, xh, xw, xchn = x.shape regs = get_ext_regions(x, kh, kw, 0) # zero padding을 포함하는 입력 regs = regs.transpose([2, 0, 1, 3, 4, 5]) # 미니배치 축을 제일 앞으로 변경 # 2차원 행렬로 모양을 변환 [출력에 해당하는 입력좌표, 필요 입력좌표] return regs.reshape([mb_size*xh*xw, kh*kw*xchn])이 함수들을 활용하여, 입력을 우리가 원하는 변수로 적절히 바꿀 수 있고, 최종적으로 얻은 변수는 [출력의 크기, 커널의 크기]이다. 다만, 여기에서의 출력의 크기는 미니배치까지 고려한 크기이고, 커널도 입력 채널의 수까지 고려한 크기이다. 이들을 활용하여, 순전파 함수를 만들면 아래와 같다.
def cnn_basic_forward_conv_layer(self, x, hconfig, pm): mb_size, xh, xw, xchn = x.shape kh, kw, _, ychn = pm['k'].shape # input의 차원을 축소 [mb X xh X xw, kh X kw X xchn] x_flat = get_ext_regions_for_conv(x, kh, kw) # kernel의 차원을 축소 [kh X kw X xchn, ychn] k_flat = pm['k'].reshape([kh*kw*xchn, ychn]) # 행렬 곱셈 결과 [mb X xh X xw, ychn] conv_flat = np.matmul(x_flat, k_flat) # reshape를 통해, output 모양으로 바꿈. conv = conv_flat.reshape([mb_size, xh, xw, ychn]) y = self.activate(conv + pm['b'], hconfig) if self.need_maps: self.maps.append(y) return y, [x_flat, k_flat, x, y] # 역전파에 사용될 보조 정보 CnnBasicModel.forward_conv_layer = cnn_basic_forward_conv_layer이렇게 하면, convolution을 간단한 행렬곱으로 변환할 수 있다. 7중 반복문을 쓰는 1번째 단계의 코드 보다, 훨씬 시간 복잡도가 작고, 행렬곱의 알고리즘으로 시간 복잡도를 대체할 수 있는 큰 장점이 있는 코드이다.
Convolution layer 역전파
위 수식을 보면 알 수 있듯, 완전 연결계층일 때와 같은 형태로 역전파가 이루어질 것을 알 수 있다. 그럼, $i,j$를 기준으로, 어떤 입출력 좌표가 연관되어 있는지 살펴보자. 아래 $x$의 인덱스는 데이터 범위를 넘어서는 값은 zero padding으로 취급한다.
$$
\begin{align}
y_{n,0,0,m} &\sim k_{i,j,l,m}x_{n,i-b_h,j-b_w,l}\\
y_{n,0,1,m} &\sim k_{i,j,l,m}x_{n,i-b_h,1+j-b_w,l}\\
\cdots\\
y_{n,0,y_w-1,m} &\sim k_{i,j,l,m}x_{n,i-b_h,y_w-1+j-b_w,l}\\
\cdots\\
y_{n,1,0,m} &\sim k_{i,j,l,m}x_{n,1+i-b_h,j-b_w,l}\\
\cdots\\
y_{n,y_h-1,0,m} &\sim k_{i,j,l,m}x_{n,y_h-1+i-b_h,j-b_w,l} \\
\cdots\\
y_{n,y_h-1,y_w-1,m} &\sim k_{i,j,l,m}x_{n,y_h-1+i-b_h,y_w-1+j-b_w,l}
\end{align}
$$$\sim$ 기호는 순전파 과정에서 영향을 준다는 의미로 사용했다. $y_h, y_w$는 출력의 크기이다. $i,j$의 커널값을 update 하기 위해선, 위 입력 데이터들을 모아서, 계산하면 된다. 즉, 역전파를 통해 convolution layer로 오는 정보를 $J$라고 하면, $k_{i,j,l,m}$으로 인해 변하는 정도는 chain rule에 의해 다음과 같이 구분할 수 있다.
$$
\frac{\partial J}{\partial k_{i,j,l,m}}=\sum_{n,r,c}\frac{\partial J}{\partial y_{n,r,c,m}}\frac{\partial y_{n,r,c,m}}{\partial k_{i,j,l,m}}$$즉, $k_{i,j,l,m}$을 update 하기 위한 변화는 각 좌표를 얼마나 변하는 지만 알면 된다. 위 식을 이용하면 이들은 $x$의 좌표로 쉽게 구할 수 있다. 정리하면,
$$
\frac{\partial J}{\partial k_{i,j,l,m}}= \sum_{n,r,c}\frac{\partial J}{\partial y_{n,r,c,m}}x_{n,r+i-b_h,c+j-b_w,l}
$$이고, 인덱스 부분을 조금 풀어 적는다면, 교과서와 같은 식이 된다. 이 식이 교과서에는 전미분 형태로 쓰여있다.
$$
\frac{\partial J}{\partial k_{i,j,l,m}}= \sum^{x_h-1}_{r=0}\sum^{x_w-1}_{c=0}\sum_{\text{minibatch} n}\frac{\partial J}{\partial y_{n,r,c,m}}x_{n,r+i-b_h,c+j-b_w,l}
$$이 앞의 layer에게 전해줄, $\frac{\partial J}{\partial x_{n,r,c,l}}$도 구해야 한다. 마찬가지로, 어떤 값에 영향을 주는지 확인해 보자. $x_{n,r,c,m}$ 값이 커널과 곱해지는 모든 경우를 고려해야 하는데, 이는 커널 모양의 각 지점과 곱해지는 경우를 생각하면 쉽다.
$$
\begin{align}
y_{n,r-b_h,c-b_w,m} &\sim k_{0,0,l,m}x_{n,r,c,l}\\
y_{n,r-b_h,c+1-b_w,m} &\sim k_{0,1,l,m}x_{n,r,c,l}\\
\cdots\\
y_{n,r-b_h,c+b_w,m} &\sim k_{0,k_w-1,l,m}x_{n,r,c,l}\\
\cdots\\
y_{n,r+1-b_h,c-b_w,m} &\sim k_{1,0,l,m}x_{n,r,c,l}\\
\cdots\\
y_{n,r+b_h,c-b_w,m} &\sim k_{k_h-1,0,l,m}x_{n,r,c,l} \\
\cdots\\
y_{n,r+b_h,r+b_w,m} &\sim k_{k_h-1,k_w-1,l,m}x_{n,r,c,l}
\end{align}
$$인덱스가 조금 어지러울 수도 있다. 우리는 위에서 $b_h$와 $b_w$를 $\{-b_a,-b_a+1, \cdots,0, \cdots, b_a-1, b_a\}$가 $k_a$의 크기를 갖게 ($a=\{h, w\})$설계했다는 것을 이해해야 한다. 즉, 여기에서, $r-b_h$부터 인덱스를 1씩 늘려나가면, $r+b_h$가 될 때가 $k_h$번째의 값임을 알 수 있다. 이는 $w$ 인덱스에서도 마찬가지이다. 위와 마찬가지 과정을 거쳐 정리하면, 아래와 같이 적을 수 있다.
$$
\frac{\partial J}{\partial x_{n,r,c,l}}=\sum_{n,i,j}\frac{\partial J}{\partial y_{n,r-b_h+i,c-b_w+j,m}}\frac{\partial y_{n,r-b_h+i,c-b_w+j,m}}{\partial x_{n,r,c,l}}=\sum_{n,i,j}\frac{\partial J}{\partial y_{n,r-b_h+i,c-b_w+j,m}}k_{i,j,l,m}
$$이것을, 위와 마찬가지로, 인덱스를 풀어쓰면, 아래와 같다.
$$
\frac{\partial J}{\partial x_{n,r,c,l}}=\sum^{k_h-1}_{i=0}\sum^{k_w-1}_{j=0}\sum_{\text{minibatch} n}\frac{\partial J}{\partial y_{n,r-b_h+i,c-b_w+j,m}}k_{i,j,l,m}
$$마찬가지로, 이를 전미분으로 적은 것이 교과서이다. 이것도 마찬가지로, 쉽게 행렬곱으로 나타내어 구현할 수 있다.
Convolution layer 역전파 구현
역전파는 순전파 과정의 역과정으로 진행하면 편하다. 사실, 수식 내용을 공부할 때는 왜 굳이 chain rule이라는 이름이 있는데, backpropagation (역전파)라는 새로운 이름을 만들었을까 했는데, 여러 가지 신경망 모델을 구현하면서 이해하게 되었다. Forward-backward algorithm의 개념에서 순전파의 반대 과정으로 진행하는 게 프로그래밍 전반에 도움이 많이 된다. 즉, 먼저 활성 함수의 미분부터 진행하고, reshape로 행렬곱으로 만들 수 있게 변환한 뒤 진행한다. 그 이후는, MLP에서 진행하는 것과 같이 연산들을 진행하면 된다.
def cnn_basic_backprop_conv_layer(self, G_y, hconfig, pm, aux): x_flat, k_flat, x, y = aux kh, kw, xchn, ychn = pm['k'].shape mb_size, xh, xw, _ = G_y.shape G_conv = self.activate_derv(G_y, y, hconfig) G_conv_flat = G_conv.reshape(mb_size*xh*xw, ychn) # reshape g_conv_k_flat = x_flat.transpose() # backprop_full_layer와 매우 흡사한 과정이다. g_conv_x_flat = k_flat.transpose() G_k_flat = np.matmul(g_conv_k_flat, G_conv_flat) G_x_flat = np.matmul(G_conv_flat, g_conv_x_flat) G_bias = np.sum(G_conv_flat, axis=0) G_kernel = G_k_flat.reshape([kh, kw, xchn, ychn]) # 4차원 텐서로 재해석 G_input = undo_ext_regions_for_conv(G_x_flat, x, kh, kw) # get_ext_regions_for_conv()의 역처리 self.update_param(pm, 'k', G_kernel) self.update_param(pm, 'b', G_bias) return G_input CnnBasicModel.backprop_conv_layer = cnn_basic_backprop_conv_layer한 가지 눈여겨보아야 할 것은, bias 항의 update이다.
G_conv_flat변수를 0 axis 방향을 따라sum을 진행하는데, 이는 당연히,ychn과 같은 크기를 갖게 된다. 즉, bias 항은 출력 채널마다 다른 값을 가지고 있다.Pooling layer
일정 영역의 대푯값을 구하는 것을 pooling이라고 한다. 주로, 최댓값이나 평균값을 이용하고, 각각 최댓값 풀링(max pooling), 평균값 풀링(average pooling)이라고 한다. 여기에서 풀링을 행하는 크기를 커널 크기(kernel size)라고 한다. 또, 몇 칸마다 풀링을 수행할지를 알려주는 보폭(stride)도 정하게 된다. 보통 이 둘은 같은 값을 같지만, 다른 값을 가져도 괜찮다. 다만, 풀링 처리에 비는 부분이나, 겹치는 영역이 생겨서 처리가 조금 불편해질 수 있다.
풀링 연산은 입력의 대푯값을 구하는 방식이기 때문에, 파라미터가 필요하지 않다. 풀링 계층은 대신, 출력되는 이미지인 특징맵(feature map)에 정보를 더 압축시키는 역할을 한다. 즉, 넓은 영역의 정보를 더 요약하여 보여준다. 주로, Convolution layer 사이에 배치되어 요약된 정보를 전달하게 된다.
Pooling layer의 역전파
앞서 말했듯, pooling layer는 파라미터를 갖지 않아서, 역전파 처리 수식에 고민할 것은 없다. 다만, max pooling, average pooling 모두 입력의 대푯값을 선출하기 때문에, 출력의 gradient를 어떤 입력에 전달할지를 고민해야 한다. max pooling의 경우 간단하게, maximum을 뽑은 위치에 전달하고, 나머지엔 모두 0을 전달하면 된다. 단, 그 위치가 여러 곳이라면, 둘 중 하나에만 임의로 전달할 것인지, 둘 다 동일하게 동일할 것인지 선택해야 한다. 교과서에 따르면, 둘 중에, 하나를 임의로 정하여 전달하는 방식이 가장 널리 이용된다고 한다.
Average pooling의 경우 모든 입력이 균등하게 반영되어 있으므로, 출력의 gradient를 모든 입력 위치에 균등하게 나누어준다. 여기에서 까다로운 점은 경계선 부근의 역전파이다. 경계선 부근에서 만약 image size가 kernel size 또는 stride의 배수가 아니어서, 경계 근처의 pooling이 다른 개수의 입력만을 이용했다면, 그 개수가 중앙 부근과 다르다. 이를 고려하여, 역전파를 수행해야 한다. Convolution layer 또한 stride로 인해 처리되지 않는 입력이 존재할 수 있는데, 이는 마찬가지로 0을 전달해 주면 된다.
CNN의 구성
CNN은 보통 convolution layer와 pooling layer를 교대로 반복하는 형태로 이루어진다. Convolution layer는 이미지의 해상도를 유지하면서 채널 수를 늘리는 방향으로 구성하는 경우가 많고, pooling layer는 채널 수를 유지하면서 해상도를 줄여 정보를 압축시키는 역할로 주로 사용한다. 채널을 여러 개로 늘리면서 한 픽셀에 이미지의 여러 다른 면을 정보로 담게 된다. 여러 convolution layer를 사용하기도 하고, 계산된 값을 응용하여 연산하기도 한다. Pooling layer는 주로 반씩 해상도를 줄여나간다. 왜냐하면, 한 번에 해상도를 확 줄이면, 정보를 충분히 반영할 수 있는 기회가 없어 학습에 지장이 가기 때문이다. 이후에, 완전연결계층(fully connected layer)을 마지막에 두어, 지역적인 정보들을 종합하여 판단한다.
교과서에서는 두 가지 예시를 집중적으로 설명한다. 한 가지는 거대 구조의 대표적인 예시인 인셉션(Inception)이고, 다른 하나는 깊은 구조의 대표적인 예시인 레스넷(Resnet)이다. 각각 이미지넷 경진대회(ILSVRC, ImageNet Large Scale Visual Recognition Challenge)에서 우승한 경력이 있는 예시이다. 인셉션은 구글에서 발표한 모델로, 인셉션 모듈이라는 병렬 처리 CNN 구조를 반복적으로 이용한 모델이다. 이후에 발표된 레스넷은 마이크로소프트에서 발표한 모델로, 많은 수의 레지듀얼 블록을 차례로 연결한 모델이다.
인셉션 (Inception)
인셉션 모델을 이해하기 위해서는, 먼저, 인셉션 모듈을 알아야 한다. 이는 하나의 입력을 여러 branch에서 서로 다른 convolution layer를 병렬 처리한 후 그 결과들을 하나로 모으는 모듈이다. 가장 기초적인 모듈은 아래와 같다.

GoogleNet (Inception-v1)의 기초 인셉션 모듈. 하나의 입력에 대해 4가지 다른 연산을 거친 후, 합병(concatenation)하게 된다. 참고로, 1x1 합성곱은 입력의 특징맵과 출력으로 나오는 특징맵의 선형관계를 나타내는 역할을 한다.
합병은 어떻게 진행될까? 합병은 굉장히 단순히, 각 출력을 출력 채널 axis를 따라 차례대로 나열한다. 4번째 있는 max pooling 층에 의해, 출력 특징맵의 크기가 입력 특징맵보다 작을 것이라고 예상할 수도 있는데, 여기에선 그렇게 이용되지 않는다. Max pooling에서 stride를 [1,1]로 지정하여, 이미지 크기를 줄이지 않고, 단순히 다른 방식의 처리를 위해 이용된다. 즉, 다른 branch에서도 같은 크기의 출력 특징맵을 위해, same 방식의 padding과 건너뛰기 없는 방식이 이용된다. 즉, 모든 branch의 출력 특징맵이 같은 크기를 갖게 되고, 이를 채널 방향으로 이어 붙인 것이 합병이다.
각 branch의 합성곱에 많은 수의 파라미터가 필요하다. 이를, 개선하기 위해 같은 논문에서 개선된 모듈을 제시한다. 도식으로 나타내면 아래와 같다.

개선된 입셉션 모듈. 먼저, 2번째 branch의 3x3 합성곱을 계산하기 전에 1x1 합성곱 계층을 두어, 입력 특징맵의 전체적인 특징을 잡고 품질을 높이려 했다. 이는, 4번째 branch의 max pooling 이후에 진행하는 것과 같은 논리이다. 이들의 추가적인 기능은 채널수 변화에도 있다.
주목해야 할 점은 3번째 branch이다. 이 branch는 5x5 합성곱 계층을 두 3x3 합성곱 계층으로 변환하였다. 입력 특징맵에서 5x5 모양을 기준으로, 본래는 5x5 커널을 이용하여 각각 곱하는 과정이었지만, 이를 두 3x3 커널을 통과시키면 똑같은 면적을 처리할 수 있다. 본래 25개의 파라미터가 필요한데, 이를 18개($=3\times 3+3\times 3$)로 많이 줄일 수 있다. 이는, 계산량을 크게 줄여 학습 속도를 빠르게 해 준다. 동시에 연산 횟수 또한 적어지는데, 5x5 커널은 한 픽셀을 계산하기 위해 25번 곱하지만, 3x3 커널을 두 번 거치게 되면, 아래와 같은 이유로, 18회($=3\times3\times9/9+3\times3$)의 곱셈으로 충분하다.

출력 한 픽셀을 위해 필요한 연산 수. 1개의 중간 특징맵을 9개의 출력 특징맵에서 공유하므로, 1번째 합성곱에 필요한 곱셈 수를 9로 나눈다. 이는 7x7 합성곱 계층을 7x1, 1x7의 두 합성곱으로 나누는 것과 같은 기술이다. 이 경우에도, 계산 부담을 49회에서 14회($=7\times7/7+7$)로 크게 낮추어 준다. 인셉션은 이를 반복하여, 아래와 같은 거대 모델을 만들어 낸다.

Inception-v1 (GoogLeNet) 의 구조. 레스넷 (ResNet)
레스넷은 대표적인 성공적인 깊은 구조 모델이다. 매우 많은 수의 레지듀얼 블록을 차례로 연결하는데, 이 전까지는 학습시키기가 매우 어려웠다. 어느 정도 이상의 깊이 증가가 정확도를 떨어뜨리는 경우가 많았다. 하지만, 이런 한계는 점차 극복되고 있다. 레지듀얼 블록(Residual block)은 아래와 같은 구조를 가지고 있다.
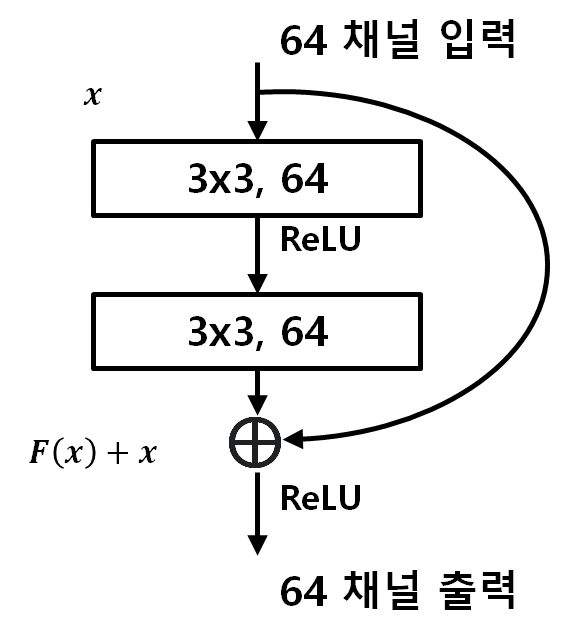
레지듀얼 블록의 구조. 위와 같은 레지듀얼 블록을 계속해서 반복함으로써, 합성곱 계층의 업데이트는 합성곱 계층에만 집중할 수 있게 하였다. 위 도식에서, 단순히 +x가 없는 플레인 블록은 같은 결과를 학습한다고 할 때, 두 개의 합성곱 계층이 +x까지 같이 학습해야 했지만, 레스넷은 이를 구별하여, 따로 더해주는 변화를 준 것이다. 마이크로소프트는 이러한 작은 변화로 상당한 성능 개선을 보여주었다.

Plain-34와 ResNet-34의 구조. 
레스넷이 보여주는 에러 감소. 이후, 더 깊은 구조로 레스넷을 확장하는 연구도 활성화된 반면, 더 깊어지면 학습이 더 어려워지기 때문에, 이를 방지하고자 레지듀얼 블록을 개선하려는 노력도 있었다. 그 노력 중 하나가 보틀넥 블록이다. 이는 레스넷-50, 101, 152와 같은 매우 깊은 구조의 레스넷 모델들에 사용되었다. 보틀넥 블록은 더 적은 수의 파라미터로 더 적은 양의 연산을 하더라도 더 큰 채널을 학습할 수 있게 응용한 것으로, 아래와 같은 구조를 갖는다.

보틀넥 블록의 구조. 그림에서의 보틀넥 블록은 채널을 줄이는 1x1 합성곱을 먼저 배치하여 적은 여러 채널을 종합한 정보를 만들어내고, 3x3 합성곱을 진행한 후, 다시 채널을 늘리는 1x1 합성곱으로 256 채널을 복원시킨다. 레지듀얼 블록에서는 64 채널 입력 특징맵을 처리하기 위해선, $3\times3\times64\times64+3\times3\times64\times64=73,728$개의 파라미터가 필요했다. 하지만, 보틀넥 블록을 사용하면, 256 채널의 입력 특징맵을 $1\times1\times256\times64 + 3\times3\times64\times64+1\times1\times64\times256=69,632$개의 파라미터로 처리 가능하다. 이는 256 채널의 큰 입력 특징맵을 처리함에도, 비슷한 수준의 파라미터로 처리 가능하다는 것을 알 수 있다. 이로써, 더 깊은 구조의 신경망을 구성할 수 있게 된 것이다. 한 가지 차이는, 3x3 합성곱이 두 번 거치면서 5x5의 입력에 출력 특징맵의 한 픽셀에 영향을 주는 반면, 보틀넥 구조는 3x3의 영역으로 줄어들게 된다. 하지만, 이는 입력이 영향을 미치는 영역의 폭이 넓어지기 때문에 영향을 미치는 방향이 달라질 뿐이다.
마치며
CNN의 기본적인 원리인 행렬 convolution은 함수해석학의 그것보다는 매우 많이 간단하다. 하지만, 이를 이용하여, 이미지라는 데이터를 분석하는 방법이 정립되었으며, 이는 ML을 주목받게 한 매우 큰 이유가 되기도 한다. 이는 일반적으로 생각하면, 서로 영향을 미치는 2d 데이터를 분석하는 방법이고, 차원은 더더욱 확장될 수 있다. 이런 면에서, CNN 모델은 여러 면에서 활용방안이 많을 것이다. 그래서, 어떤 식으로 구현되는지 정확하게 알고 있는 것이 좋다고 생각했다. 이 글이 내부 구조를 보고자 하는 이들에게 도움이 되길 바란다.
참고 문헌
'Study > Machine learning' 카테고리의 다른 글
머신러닝 기초 공부; Adam (1) 2023.11.26 머신러닝 기초 공부; SLP, MLP (0) 2023.11.26 LightGBM 논문 공부 (0) 2023.11.26 이전글이 없습니다.댓글